Recently, I discovered a very interesting radio show hosted by Giannis Petridis on ert. Giannis is hosting one of the longest surviving radio shows in Greece and has one of the biggest record collections in the world. In his show he mostly suggests new artists and albums that are not promoted by mainstream media so it’s a great way for discovering new music. After listening a few of his shows I discovered some hidden gems so I started to think of a way to extract all these data without having to listen to all of his shows.
Data collection Link to heading
Fortunately a lot of the shows are available on demand so first, I had to download everything locally. Ert’s website hosts the shows starting from 2017 up until today. After fiddling around the website I found that you can easily access the .mp3 files by a specific URL. The URLs follow a rather simple naming scheme which is {year}{month}{day} and some constant text. In order to store them locally I wrote this simple python script.
#!/usr/bin/python3
import requests
url = "https://audio.ert.gr/radio/proto/apo-tis-4-stis-5/{}{}{}-apo-tis-4-stis-5.mp3"
# Iterate through available dates
for year in range(2017, 2021):
for month in range(1, 13):
for day in range(1, 32):
month_s = str(month)
day_s = str(day)
if month < 10:
month_s = "0" + month_s
if day < 10:
day_s = "0" + day_s
url_to_dl = url.format(str(year), month_s, day_s)
response = requests.get(url_to_dl)
total = response.headers.get('content-length')
print(url_to_dl)
if total is None:
print("File not found")
else:
with open("./{}{}{}.mp3".format(str(year), month_s, day_s), 'wb') as f:
for data in response.iter_content(chunk_size=2048):
f.write(data)After running the script for a while I ended up with 662 .mp3 files (~40Gb) that I had to somehow analyze and export the metadata.
Analyzing Data Link to heading
The first thing that came to mind was to use a service like Shazam. Shazam is a music identification service where by submitting a short sample of audio it can identify which song that is. An interesting article about how audio identification works can be found here: https://oxygene.sk/2011/01/how-does-chromaprint-work/
Unfortunately Shazam does not offer an API but there are other services that we can use. I had a look at AcoustID, an open source audio identification service which comes with an open library of fingerprints but the drawback is that it matches only full length songs which means that I could not use it in the context of a radio show.
In the end I ended up using AudD, a paid service which provides a very simple API in order to identify audio files. The first approach that I used in order to identify all the songs was to split each radio show into 10sec segments and scan one every 10 segments in order to reduce the requests but also make sure that I wasn’t skipping any song. For splitting the tracks I used pydub.
The python script for doing this can be seen below.
#!/usr/bin/python3
import requests
import os
from pydub import AudioSegment
data = {
'api_token': 'XXXXXXXXXXXXXXX',
'return': 'apple_music,spotify',
}
# Iterate through files
directory = os.fsencode('.')
for file in os.listdir(directory):
filename = os.fsdecode(file)
filename_out = os.path.splitext(filename)[0] + '.json'
if filename.endswith('.mp3'):
print('Splitting: ' + filename)
radio_show = AudioSegment.from_mp3(filename)
# Split audio in 10 sec chucks and only use 1 every 60 sec.
with open(filename_out, 'a+') as out_f:
for i, chunk in enumerate(radio_show[::10000]):
if not (i % 10):
continue
chunk.export('temp.mp3', format='mp3')
result = requests.post('https://api.audd.io/', data=data, files={'file' : open('temp.mp3', 'rb')})
out_f.write(result.text)The total amount of requests needed is around 166K which based on the service’s pricing would require $840. I tried to further reduce the requests by using 1 segment every 3 min given the assumption that each track is more than 3 min long. This drops the requests to ~55K but still, I needed something better.
Speech Segmentation Link to heading
Ideally I’d want to split every raw file to segments of speech and music. This falls under the field of Speech Segmentation and as with everything nowadays there is a pre-trained python module called inaSpeechSegmenter that allows us to detect speech, music and speaker gender. After setting it up, the first thing was to try and segment a single radio show and check if the results are correct.
Running the code snippet below,
from inaSpeechSegmenter import Segmenter, seg2csv
media = './media/musanmix.mp3'
seg = Segmenter()
segmentation = seg(media)
print(segmentation)yields the first results:
[('noEnergy', 0.0, 0.6), ('music', 0.6, 64.28), ('male', 64.28, 66.7), ('noEnergy', 66.7, 67.34), ('male', 67.34, 68.72), ('noEnergy', 68.72, 69.24), ('male', 69.24, 75.34), ('noEnergy', 75.34, 76.3), ('male', 76.3, 78.38), ('noEnergy', 78.38, 78.76), ('noise', 78.76, 79.08), ('noEnergy', 79.08, 79.52), ('male', 79.52, 84.5), ('noEnergy', 84.5, 86.06), ('male', 86.06, 88.08), ('noEnergy', 88.08, 88.7), ('male', 88.7, 90.9), ('noEnergy', 90.9, 91.60000000000001), ('male', 91.60000000000001, 95.06), ('noEnergy', 95.06, 96.06), ('music', 96.06, 128.9), ('male', 128.9, 144.04), ('noEnergy', 144.04, 144.68), ('male', 144.68, 155.4), ('noEnergy', 155.4, 156.58), ('male', 156.58, 158.34), ('noEnergy', 158.34, 158.96), ('male', 158.96, 160.38), ('noEnergy', 160.38, 160.88), ('male', 160.88, 162.86), ('noEnergy', 162.86, 164.22), ('male', 164.22, 166.34), ('noEnergy', 166.34, 167.48), ('male', 167.48, 179.72), ('noEnergy', 179.72, 180.74), ('male', 180.74, 182.42000000000002), ('noEnergy', 182.42000000000002, 184.0), ('male', 184.0, 198.4), ('noEnergy', 198.4, 198.84), ('male', 198.84, 212.34), ('noEnergy', 212.34, 212.72), ('male', 212.72, 274.08), ('music', 274.08, 279.26), ('noise', 279.26, 287.88), ('music', 287.88, 289.78000000000003), ('noise', 289.78000000000003, 292.38), ('music', 292.38, 298.5), ('male', 298.5, 309.74), ('noEnergy', 309.74, 310.32), ('male', 310.32, 362.06), ('noEnergy', 362.06, 362.7), ('male', 362.7, 364.0), ('noEnergy', 364.0, 364.66), ('male', 364.66, 406.46000000000004), ('noEnergy', 406.46000000000004, 406.96000000000004), ('male', 406.96000000000004, 494.76), ('noEnergy', 494.76, 495.22), ('male', 495.22, 503.76), ('noEnergy', 503.76, 504.24), ('male', 504.24, 553.1800000000001), ('noEnergy', 553.1800000000001, 554.16), ('male', 554.16, 563.6), ('female', 563.6, 568.66), ('male', 568.66, 581.78), ('noEnergy', 581.78, 582.22), ('male', 582.22, 601.22), ('noEnergy', 601.22, 601.6800000000001), ('male', 601.6800000000001, 606.44), ('noEnergy', 606.44, 607.14), ('male', 607.14, 607.66), ('noEnergy', 607.66, 608.0600000000001), ('male', 608.0600000000001, 643.32), ('noEnergy', 643.32, 643.72), ('male', 643.72, 647.1800000000001), ('noEnergy', 647.1800000000001, 647.76), ('male', 647.76, 665.88), ('noEnergy', 665.88, 666.3000000000001), ('male', 666.3000000000001, 694.38), ('noEnergy', 694.38, 694.78), ('male', 694.78, 712.02), ('noEnergy', 712.02, 712.46), ('male', 712.46, 760.72), ('noEnergy', 760.72, 762.3000000000001), ('noise', 762.3000000000001, 772.66), ('music', 772.66, 877.4200000000001), ('noise', 877.4200000000001, 881.9200000000001), ('noEnergy', 881.9200000000001, 882.52), ('male', 882.52, 916.12), ('noEnergy', 916.12, 916.62), ('male', 916.62, 928.74), ('noEnergy', 928.74, 929.3000000000001), ('male', 929.3000000000001, 940.4200000000001), ('noEnergy', 940.4200000000001, 941.12), ('male', 941.12, 943.38), ('noEnergy', 943.38, 943.84), ('male', 943.84, 963.46), ('music', 963.46, 1185.58), ('noEnergy', 1185.58, 1187.22), ('music', 1187.22, 1202.66), ('male', 1202.66, 1215.08), ('music', 1215.08, 1221.34), ('male', 1221.34, 1254.8600000000001), ('music', 1254.8600000000001, 1258.84), ('male', 1258.84, 1296.72), ('music', 1296.72, 1432.38), ('male', 1432.38, 1467.04), ('noEnergy', 1467.04, 1467.58), ('male', 1467.58, 1473.68), ('noEnergy', 1473.68, 1474.76), ('male', 1474.76, 1480.68), ('music', 1480.68, 1490.84), ('male', 1490.84, 1493.14), ('music', 1493.14, 1762.32), ('male', 1762.32, 1781.02), ('noEnergy', 1781.02, 1781.72), ('male', 1781.72, 1817.4), ('noEnergy', 1817.4, 1818.26), ('male', 1818.26, 1826.16), ('noEnergy', 1826.16, 1827.1000000000001), ('male', 1827.1000000000001, 1828.02), ('noEnergy', 1828.02, 1828.48), ('male', 1828.48, 1831.06), ('noEnergy', 1831.06, 1831.6000000000001), ('music', 1831.6000000000001, 1835.74), ('male', 1835.74, 1838.78), ('music', 1838.78, 1841.28), ('male', 1841.28, 1847.22), ('music', 1847.22, 2053.06), ('male', 2053.06, 2058.02), ('music', 2058.02, 2059.38), ('male', 2059.38, 2090.3), ('noEnergy', 2090.3, 2090.7), ('male', 2090.7, 2098.68), ('noEnergy', 2098.68, 2099.92), ('male', 2099.92, 2105.68), ('noEnergy', 2105.68, 2106.76), ('male', 2106.76, 2110.16), ('noEnergy', 2110.16, 2111.0), ('male', 2111.0, 2115.2200000000003), ('noEnergy', 2115.2200000000003, 2116.44), ('male', 2116.44, 2127.06), ('music', 2127.06, 2130.8), ('male', 2130.8, 2132.44), ('music', 2132.44, 2309.18), ('male', 2309.18, 2346.04), ('noEnergy', 2346.04, 2346.44), ('male', 2346.44, 2352.9), ('noEnergy', 2352.9, 2354.38), ('male', 2354.38, 2383.58), ('music', 2383.58, 2474.7200000000003), ('male', 2474.7200000000003, 2513.5), ('noEnergy', 2513.5, 2514.2200000000003), ('male', 2514.2200000000003, 2538.7000000000003), ('noEnergy', 2538.7000000000003, 2541.9), ('male', 2541.9, 2546.0), ('music', 2546.0, 2547.7200000000003), ('female', 2547.7200000000003, 2548.64), ('noEnergy', 2548.64, 2550.12), ('music', 2550.12, 2618.9), ('noEnergy', 2618.9, 2619.78), ('music', 2619.78, 2666.78), ('noEnergy', 2666.78, 2667.66), ('music', 2667.66, 2762.86), ('noEnergy', 2762.86, 2764.2400000000002), ('music', 2764.2400000000002, 2778.4), ('noEnergy', 2778.4, 2779.62), ('music', 2779.62, 2804.2400000000002), ('noEnergy', 2804.2400000000002, 2806.64)]Opening the file, I was happy to verify that the music segments matched exactly. Putting everything together I created a script that will take a 10s sample from each segment and send it for identification to AudD.
#!/usr/bin/python3
import requests
import os
import sys
from inaSpeechSegmenter import Segmenter, seg2csv
from pydub import AudioSegment
data = {
'api_token': 'XXXXXXXXXXXXXXX',
'return': 'spotify',
}
if (len(sys.argv)) < 3:
print('Usage: ' + sys.argv[0] + ' <input.mp3> <output.json>')
sys.exit(0)
filename = sys.argv[1]
filename_out = sys.argv[2]
# Segment audio
seg = Segmenter()
segmentation = seg(filename)
# Get music timestamps and keep only
# the ones that are >10s
music_timestamps = [m for m in segmentation if ((m[0] == 'music') and (m[2] - m [1] > 10))]
total_requests = 0
# Iterate timestamps and send for identification
radio_show = AudioSegment.from_mp3(filename)
with open(filename_out, 'a+') as out_f:
for m in music_timestamps:
start_ms = int(m[1] * 1000)
chunk = radio_show[start_ms:start_ms + 10000]
chunk.export('temp.mp3', format='mp3')
result = requests.post('https://api.audd.io/', data=data, files={'file' : open('temp.mp3', 'rb')})
total_requests += 1
out_f.write(result.text)
print(total_requests)Spotify playlist Link to heading
After I got the json response with the songs the next step was to create a Spotify playlist. The first step was to register a new app on Spotify for developers

and then I used spotipy in order to access the API and add the tracks to my playlist:
#!/usr/bin/python3
import spotipy
from spotipy.oauth2 import SpotifyOAuth
sp = spotipy.Spotify(auth_manager=SpotifyOAuth(client_id="XXXX",
client_secret="XXXX",
redirect_uri="https://mispyrou.com",
scope="playlist-modify-private playlist-modify",
open_browser=False))
playlist_url = 'https://open.spotify.com/playlist/66bZtV2zrv49F28hS8ffbk'
username = 'mpekatsoula'
track_ids = ['TRACK_01', 'TRACK_O2']
results = sp.user_playlist_add_tracks(username, playlist_url, track_ids)After putting everything together and by making sure that I don’t add any duplicate songs, it was time to run the script. Running it on a single 60min radio show takes around 2min on a NVIDIA GTX 1060 which is quite reasonable.
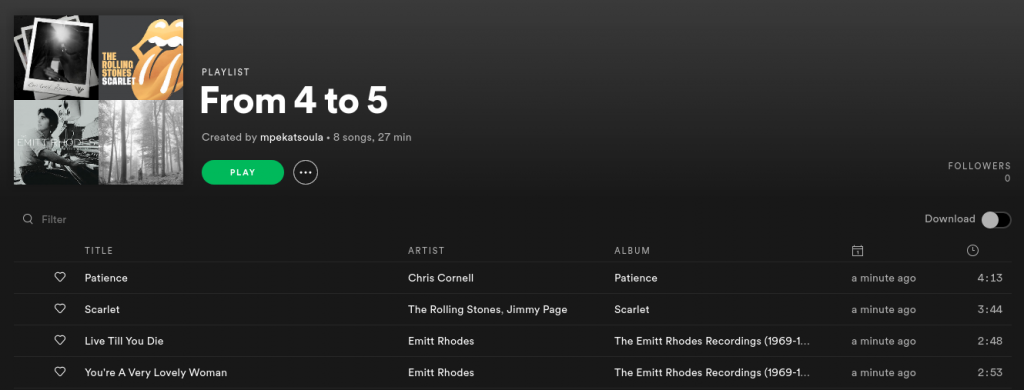
And in case you are still wondering, I managed to drop my total requests to AudD to ~10K!